
Published by
Published on
February 1, 2022




The day-to-day at Optilogic is constantly changing (and fun), and the way that users implement our software has continued to surprise and inspire us. In a recent project, we built out an application that combined both demand analytics and optimization for short and long term supply chain development.
While the marketplace has often overused the terms Artificial Intelligence (AI) and Machine Learning (ML), these technologies and algorithms have come a long way. We’ve discovered innovative ways to blend and leverage both capabilities as they are currently designed with demand and optimization at their foundation. Here’s how you can leverage both in your demand analytics forecasting.
There are numerous Python-based, open-sourced solvers that companies and analysts can incorporate in Atlas. Rather than restricting access, we purposefully designed our platform to be open and play well with others. Atlas allows you to combine other solvers or create stand-alone solutions that produce accurate and reliable demand analytics.
Some of these are more of your traditional statistical algorithms, while others incorporate some level of machine learning. A few that we used on a recent project are listed below with a brief description of what they do. If you want us to go more in-depth on these use cases, let’s chat.
Long short-term memory (LSTM) is an artificial recurrent neural network architecture used in the field of deep learning. Unlike standard feedforward neural networks, LSTM has feedback connections. LSTM can model complex relationships from the data and remove the outliers. It can even capture trends and seasonality with a complex internal dynamic, all without the use of detailed parameters for the user to input.
Imagine not having to do excessive manual and rigorous tuning for an LSTM model! This means you can leverage advanced technology without having to incorporate external factors that other neural networks require to be effective.
Facebook Prophet is an open-source library, based on decomposable models. It's a complex statistical model with many parameters and flexibility to tune. While this allows more control over your models, it also invites unpredictable outcomes if you don’t fully understand their impact. In Prophet, these parameters are tuned based on grid search.
Prophet is a procedure that forecasts time series data based on an additive model where non-linear trends are fit with yearly, weekly and daily seasonality, plus holiday effects. It works best with time series that have strong seasonal effects and a wide range of historical data. Prophet is robust to missing data and shifts in the trend, and typically handles outliers well.
ARIMA is an acronym for “autoregressive integrated moving average.” It’s a model used in statistics and econometrics to measure events that happen over a period of time. The model is used to understand past data or predict future data in a series. It’s most common to see this model when a metric is recorded in regular intervals, from fractions of a second to daily, weekly or monthly periods. ARIMA is a type of model known as a Box-Jenkins method.
Moving Average is another old school model used to predict demand. It comes in quite handy for low volume items, new products with little history, and for items with some basic variability but no trend/seasonality.
Exponential Smoothing is a time series forecasting method for univariate data. Time series methods, like the Box-Jenkins ARIMA family of methods, develop a model where the prediction is a weighted linear sum of recent past observations or lags. Exponential Smoothing forecasting methods are similar, in that a prediction is a weighted sum of past observations, but the model explicitly uses an exponentially decreasing weight for past observations. Specifically, past observations are weighted with a geometrically decreasing ratio.
Triple Exponential Smoothing is an extension of Exponential Smoothing that explicitly adds support for seasonality to the univariate time series. This method is sometimes called Holt-Winters Exponential Smoothing, named for the method’s contributors, Charles Holt and Peter Winters.
In addition to the alpha and beta smoothing factors, a new parameter is added called gamma (g) that controls the influence on the seasonal component. As with the trend, the seasonality may be modeled as either an additive or multiplicative process for a linear or exponential change in the seasonality.
Additive Seasonality: Triple Exponential Smoothing with a linear seasonality.
Multiplicative Seasonality: Triple Exponential Smoothing with an exponential seasonality.
So why does a company need multiple algorithms? We did a small analysis during this project to help answer this question. We used the moving average for a sample of SKUs and compared the results of using just the moving average to the multi-algorithm select process that we built for the demand analytics application.
Turns out there was a 22% improvement in weekly SKU level performance by using multiple algorithms versus a moving average model. The range of improvement across all of the algorithms is shown below:
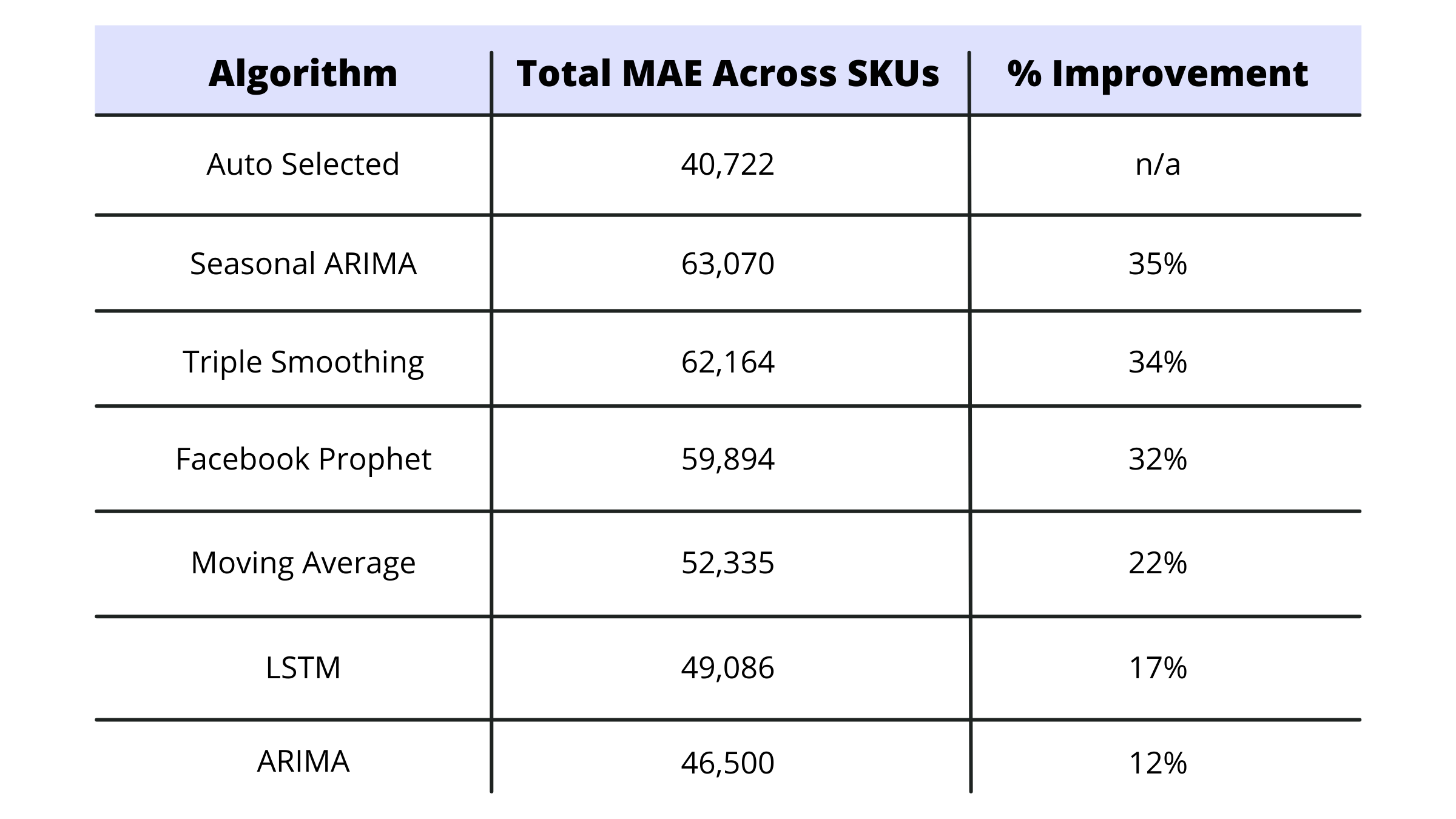
Keep in mind that SKUs have different demand characteristics, so everyone's results will be a bit different. But it's interesting to show the power of using a mix of old and new technology to improve demand. It’s important to note that even with the newer, more hyped methods, forecasts will always be off—and there’s nothing better than human interaction, communication, and insights to further improve what algorithms may be saying.
You can use our supply chain design solution Cosmic Frog to build tailored solutions using Python code to link to a simulation or optimization model. Alternatively, we can use our pre-built APIs to feed the demand outputs into a visual analytics application like PowerBI. These types of processes can be automated and repeated with ease.
For small to medium-sized businesses that can't afford hundreds of thousands of dollars for advanced solving technologies, Optilogic has a solution that is affordable, scalable, and just as powerful as the platform solutions charging millions.
Want to learn more? Explore our pricing packages and see which tier is right for you.
John Ames
John is the Vice President of Business Development at Optilogic. Prior to joining, he was part of the leadership team at LLamasoft, Inc. helping the company go from 12 people to over 500 across 10 years, with roles in pre-sales, professional services, alliances, and country manager. John also worked in pre-sales and business development roles for several small supply chain companies with technologies in inventory optimization, demand planning and causal forecasting, network optimization, S&OP, and finite capacity scheduling.
The day-to-day at Optilogic is constantly changing (and fun), and the way that users implement our software has continued to surprise and inspire us. In a recent project, we built out an application that combined both demand analytics and optimization for short and long term supply chain development.
While the marketplace has often overused the terms Artificial Intelligence (AI) and Machine Learning (ML), these technologies and algorithms have come a long way. We’ve discovered innovative ways to blend and leverage both capabilities as they are currently designed with demand and optimization at their foundation. Here’s how you can leverage both in your demand analytics forecasting.
There are numerous Python-based, open-sourced solvers that companies and analysts can incorporate in Atlas. Rather than restricting access, we purposefully designed our platform to be open and play well with others. Atlas allows you to combine other solvers or create stand-alone solutions that produce accurate and reliable demand analytics.
Some of these are more of your traditional statistical algorithms, while others incorporate some level of machine learning. A few that we used on a recent project are listed below with a brief description of what they do. If you want us to go more in-depth on these use cases, let’s chat.
Long short-term memory (LSTM) is an artificial recurrent neural network architecture used in the field of deep learning. Unlike standard feedforward neural networks, LSTM has feedback connections. LSTM can model complex relationships from the data and remove the outliers. It can even capture trends and seasonality with a complex internal dynamic, all without the use of detailed parameters for the user to input.
Imagine not having to do excessive manual and rigorous tuning for an LSTM model! This means you can leverage advanced technology without having to incorporate external factors that other neural networks require to be effective.
Facebook Prophet is an open-source library, based on decomposable models. It's a complex statistical model with many parameters and flexibility to tune. While this allows more control over your models, it also invites unpredictable outcomes if you don’t fully understand their impact. In Prophet, these parameters are tuned based on grid search.
Prophet is a procedure that forecasts time series data based on an additive model where non-linear trends are fit with yearly, weekly and daily seasonality, plus holiday effects. It works best with time series that have strong seasonal effects and a wide range of historical data. Prophet is robust to missing data and shifts in the trend, and typically handles outliers well.
ARIMA is an acronym for “autoregressive integrated moving average.” It’s a model used in statistics and econometrics to measure events that happen over a period of time. The model is used to understand past data or predict future data in a series. It’s most common to see this model when a metric is recorded in regular intervals, from fractions of a second to daily, weekly or monthly periods. ARIMA is a type of model known as a Box-Jenkins method.
Moving Average is another old school model used to predict demand. It comes in quite handy for low volume items, new products with little history, and for items with some basic variability but no trend/seasonality.
Exponential Smoothing is a time series forecasting method for univariate data. Time series methods, like the Box-Jenkins ARIMA family of methods, develop a model where the prediction is a weighted linear sum of recent past observations or lags. Exponential Smoothing forecasting methods are similar, in that a prediction is a weighted sum of past observations, but the model explicitly uses an exponentially decreasing weight for past observations. Specifically, past observations are weighted with a geometrically decreasing ratio.
Triple Exponential Smoothing is an extension of Exponential Smoothing that explicitly adds support for seasonality to the univariate time series. This method is sometimes called Holt-Winters Exponential Smoothing, named for the method’s contributors, Charles Holt and Peter Winters.
In addition to the alpha and beta smoothing factors, a new parameter is added called gamma (g) that controls the influence on the seasonal component. As with the trend, the seasonality may be modeled as either an additive or multiplicative process for a linear or exponential change in the seasonality.
Additive Seasonality: Triple Exponential Smoothing with a linear seasonality.
Multiplicative Seasonality: Triple Exponential Smoothing with an exponential seasonality.
So why does a company need multiple algorithms? We did a small analysis during this project to help answer this question. We used the moving average for a sample of SKUs and compared the results of using just the moving average to the multi-algorithm select process that we built for the demand analytics application.
Turns out there was a 22% improvement in weekly SKU level performance by using multiple algorithms versus a moving average model. The range of improvement across all of the algorithms is shown below:
Keep in mind that SKUs have different demand characteristics, so everyone's results will be a bit different. But it's interesting to show the power of using a mix of old and new technology to improve demand. It’s important to note that even with the newer, more hyped methods, forecasts will always be off—and there’s nothing better than human interaction, communication, and insights to further improve what algorithms may be saying.
You can use our supply chain design solution Cosmic Frog to build tailored solutions using Python code to link to a simulation or optimization model. Alternatively, we can use our pre-built APIs to feed the demand outputs into a visual analytics application like PowerBI. These types of processes can be automated and repeated with ease.
For small to medium-sized businesses that can't afford hundreds of thousands of dollars for advanced solving technologies, Optilogic has a solution that is affordable, scalable, and just as powerful as the platform solutions charging millions.
Want to learn more? Explore our pricing packages and see which tier is right for you.
John Ames
John is the Vice President of Business Development at Optilogic. Prior to joining, he was part of the leadership team at LLamasoft, Inc. helping the company go from 12 people to over 500 across 10 years, with roles in pre-sales, professional services, alliances, and country manager. John also worked in pre-sales and business development roles for several small supply chain companies with technologies in inventory optimization, demand planning and causal forecasting, network optimization, S&OP, and finite capacity scheduling.
Fill out the form to unlock the full content
.jpg)



.png)
.png)

.png)